

Quante volte vi è capitato di aver perso un file e di non avere un backup per recuperarlo?
Ed ecco in arrivo il déjà vu di quella volta in cui... (riempite pure voi i puntini)
Irritante, vero? Frustrante, vero?
A volte la perdita di un dato ci complica la giornata più che per la perdita intrinseca per ciò che ne comporti. Un po’ come quando perdi il portafoglio, blocchi le carte dal telefono e tolti i contanti che potevi avere e il valore del portafoglio in sé, è molto più stressante dover richiedere tutti i duplicati dei documenti. Quel tempo, quello stress, nessuno ve lo ripagherà più.
In un precedente articolo abbiamo introdotto la differenza tra server e dominio ed abbiamo capito che sostanzialmente il dominio è solamente “l’etichetta” che indica il contenuto di una certa “scatola” mentre il server è la scatola vera e propria.
Come tutte le scatole, anche la funzione del server è quella di contenere cose, in questo caso non oggetti che non sappiamo dove altro collocare ma migliaia di file di codice, immagini, documenti e tutto quanto necessario a comporre il nostro software (questo a prescindere dalla filosofia tecnologica scelta dal vostro fornitore o in condivisione con lui).
È facile perdere i dati di un server?

Statisticamente con i nostri standard aziendali non è per niente probabile perderli. E’ molto più probabile perdere il portafoglio o le chiavi di casa ma dal momento che ogni dato digitale può essere spostato nel cestino, che si tratti del cellulare, computer o server poco cambia, esiste in effetti la remota possibilità che accada anche al vostro software o a parte di esso.
Ora, senza voler entrare in questioni legate al perché ciò possa accadere e quindi alle due macro aree:
- sicurezza informatica, hacking, cracking ecc. di cui non dovete preoccuparvi poiché già ci pensiamo noi a mettervi al sicuro
- e alla ben più pericolosa “Buongiorno, sono il cliente, forse ho inavvertitamente cancellato tutto”
soffermiamoci solamente sullo scenario in cui abbiamo perso dei dati o li abbiamo messi in disordine e dobbiamo “tornare indietro” nel tempo.
Che tipi di dati potrei perdere in un server?

Finché si tratta del solo codice sviluppato da noi di ASB\COMUNICAZIONE non ci sono problemi, poiché ogni progetto che eroghiamo viene versionato fin dalla prima riga su server separato da quello del cliente e qualora ci accorgessimo di qualche problema possiamo sempre correggerlo o tornare indietro, come descritto in questo articolo sui principi di versionamento e stesura collaborativa dei sorgenti.
Il codice sviluppato da noi però non è tutto ciò che ci possa essere nel server, ci sono infatti anche:
- i file che compongono il sistema operativo, che tipicamente è Linux nel nostro caso. Eh si, anche il tuo applicativo web, dalla semplice landing promozionale al complesso gestionale di produzione ha bisogno, come tutti i software, di un ambiente compatibile in cui girare, come Word ha bisogno di Windows per dire.
- i contenuti che vengono caricati dagli utilizzatori, che siano admin o end-user, e questi dati possono essere testi (il commento ad un post del blog), immagini (di una nuova linea di prodotto), documenti (certificati pdf e datasheet ad esempio) e molto altro che per ragioni di privacy non disponiamo in quanto non inerenti al software ma più all’uso che ne viene fatto. Noi abbiamo costruito la casa e ti abbiamo consegnato le chiavi, il colore delle salviette o quello che decidi di cucinare è affar tuo, noi non lo sappiamo.
Quindi per riassumere possiamo dire che dentro un server troviamo sostanzialmente 3 diversi tipi di dati:
- il sistema operativo
- il software sviluppato su quel sistema operativo
- i contenuti inseriti dagli utilizzatori attraverso quel software
Cosa succede se perdo i dati del mio server?

Abbiamo capito che in merito al punto 2 non ci sono rischi poiché una copia è già in nostro possesso, da sempre, fin dalla nascita dell’applicativo. A prescindere però dalle cause e dalle probabilità non possiamo esimerci dallo strutturare un’efficace politica di backup e di recupero dei dati specialmente per i punti 1 e 3, così da garantire sonni tranquilli sia a noi che ai clienti che agli interlocutori dei nostri clienti.
La perdita di dati, in funzione del tipo di dato perso, può non essere un reale problema ma può anche causare gravi danni economici ad un’azienda. Di conseguenza più i dati memorizzati in un server sono importanti o preziosi e più la policy di backup dovrà essere adeguata, bilanciando sapientemente i due estremi:
- da un lato la sottostruttura che potrebbe esporre i dati ad un eccessivo pericolo
- dall’altro la sovrastruttura che potrebbe aumentare inutilmente i costi
Come spesso accade “la virtù sta nel mezzo”, cit.
Perché si parla anche di recovery policy e non solo di backup?

Ancor prima che il GDPR sottolineasse la questione suggerendo di adottare protocolli specificatamente inerenti il data-breach, il concetto era ben noto agli addetti ai lavori: se in generale possiamo definire il backup come l’attività di salvataggio di una copia dei dati (incrementale o meno, scatenata temporalmente o mediante eventi che sia), il recovery è l’attività di ripristino, di questi dati, ovvero: posto che abbia eseguito il backup e che quindi abbia messo in sicurezza i dati, qualora ne abbia bisogno cosa e come devo fare per ri-ottenerli? E soprattutto, quanto tempo è necessario?
In questo contesto il tempo è fondamentale: immaginiamo un e-commerce che esegue molteplici vendite ogni ora, uno stop per il recupero dei dati di un giorno potrebbe non essere la soluzione più idonea.
L’argomento prende una piega più ampia quindi:
- cosa salvo e come lo salvo (backup)
- come e in quanto tempo lo recupero (recovery)
Di nuovo anche qui subentra il tema bilanciamento prestazioni/flessibilità/effort/costi: i dati più importanti e/o i dati relazionati a quelli più importanti è bene che abbiano policy di recupero rapido, il più rapido possibile (nell’ordine di qualche secondo), mentre per dati meno indispensabili si può anche pensare a tempi più lunghi (nell’ordine di qualche minuto).
Quali servizi offriamo a riguardo?
A seconda delle esigenze o delle volontà offriamo differenti livelli di backup e recupero, via via più granulari. Grazie alle infrastrutture cloud che progettiamo per conto dei nostri clienti, peraltro, il costo vivo dello storage dei dati non è elevato come accade in contesti più classici (per non dire antichi) e quindi il costo vero e proprio è solamente quello una tantum da corrispondere per lo sviluppo in sé dell'una o dell’altra soluzione, non tanto quello delle conseguenze di queste attività in termini di GB occupati.
Attenzione però, tutto questo discorso funziona ed è economicamente davvero vantaggioso per voi se scegliete di affidarci la progettazione completa della vostra infrastruttura. Se disponete di macchine e/o reti fornite da altri e volete solo assicurare i dati al meglio possiamo certamente lavorare insieme ma i tempi e l’effort sono ovviamente più dilatati, in contesti ibridi.
Lo snapshot della macchina
Questo servizio è sempre compreso in tutte le nostre progettazioni ed implementazioni di architetture cloud con Amazon AWS. Lo snapshot della macchina è di fatto una fotografia dell’intero server che comprende quindi il salvataggio di una copia di tutti e 3 i tipi di dati: il sistema operativo, il codice e i contenuti inseriti dagli utenti.
Facciamo eseguire in automatico questo backup ogni giorno per 30 giorni, nell’orario in cui si ha meno traffico, ad esempio di notte.
Lo snapshot è un tipo di backup incrementale e quindi salvo la prima esecuzione, in cui deve fotografare tutto il contenuto, è molto veloce nelle successive poichè memorizza esclusivamente le modifiche rispetto allo snapshot preso in precedenza.
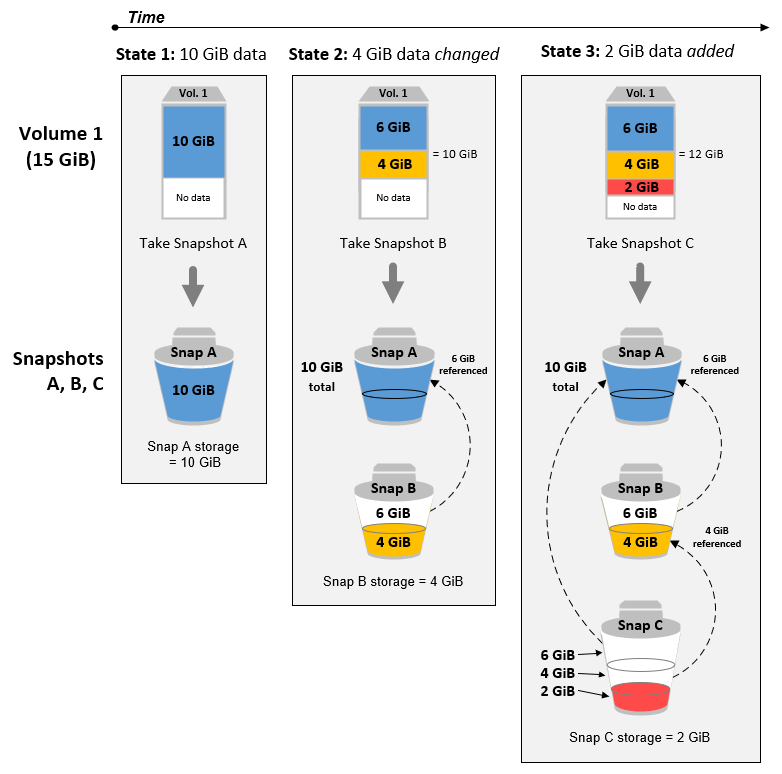
Lo snapshot ci consente un basso recovery time: dal momento in cui riceviamo la segnalazione di richiesta di ripristino avviamo una nuova macchina nella medesima rete a partire dallo snapshot di nostro interesse e non appena pronta ruotiamo l’indirizzo IP (che per nostra policy è sempre elastico) dalla vecchia alla nuova istanza. Tradotto in tempi parliamo di massimo 2 minuti, a volte anche molto meno.
Il backup dell’applicazione
Questo è un servizio aggiuntivo a quello precedente e viene utile quando si vuole avere a disposizione anche la sola porzione riguardante l’applicazione sviluppata oltre alla fotografia dell’intera macchina. Ciò può essere interessante per vari motivi, tra cui ad esempio:
- voglio poter gestire il codice dell’applicazione in maniera svincolata dal sistema operativo, ad esempio per spostarlo velocemente su macchine diverse
- voglio poter recuperare l’applicazione ma senza dover rifare gli aggiornamenti al sistema operativo già eseguiti, ad esempio nel caso in cui l’attività di aggiornamento del sistema operativo e quella di perdita dei dati siano avvenute lo stesso giorno e quindi lo snapshot valido più recente mi aiuti in un senso ma non nell’altro
Questo genere di backup normalmente non si effettua nello stesso momento del precedente, ma anche con qualche ora di differenza, in modo da poter gestire in maniera più granulare la scelta in caso di recupero. I tempi non sono più così immediati: a seconda della complessità del progetto potrebbe essere necessario impiegare anche una o due ore, ma qualora i tempi per la riesecuzione manuale delle modifiche al sistema operativo dovessero richiedere più tempo ancora si tratterebbe di un’attesa certamente giustificabile se la si analizza da un punto di vista globale.
Il backup del database
In ultimo un ulteriore servizio aggiuntivo, che non va in conflitto con i precedenti e che quindi può essere considerato come un vero e proprio terzo sistema parallelo di backup, in quei casi in cui si vuole avere anche un backup dedicato e puntuale dei soli dati contenuti nei database. Questo genere di backup è molto utile in casi piuttosto estremi tra loro:
- casi in cui il sistema operativo e l’applicazione non subiscano grosse variazioni nel tempo, al contrario dei contenuti. Immaginiamo ad esempio un sito di news: tanti contenuti informativi ogni giorno ma non per forza anche modifiche alle funzioni offerte dalla piattaforma. Solo tanti testi in più ogni giorno. Ecco che avere una copia del solo database diventa molto comodo perché mi consente di ripristinare le sole informazioni perse senza dover ripristinare tutta l’applicazione o tutta la macchina.
- oppure, al contrario, immaginiamo il caso in cui l’applicazione, la macchina e i contenuti subiscano continue modifiche giornaliere e vadano persi solo i contenuti. Sarebbe complesso dover non solo effettuare tutte le modifiche al software ed in aggiunta re-inserire tutti i dati mancanti, magari dopo anni di pubblicazioni. In questo modo invece se abbiamo solo perso/cancellato i dati del database possiamo occuparci di ripristinare solo quelli.
Questo tipo di backup può essere effettuato ogni giorno, anche per 60 giorni, anche più volte al giorno. Il ripristino è velocissimo, spesso anche meno rispetto al ripristino dello snapshot, a volte parliamo davvero di qualche secondo.
Per applicazioni standard solitamente questo è il nostro modo di vedere l’argomento ma possiamo spaziare verso soluzioni super personalizzate e/o altamente complesse in funzione delle necessità e della complessità del progetto.
Vuoi sapere se i tuoi dati siano adeguatamente protetti o magari preferisci valutare di migliorare ulteriormente le tue policy di backup e recupero dei dati? Contattaci, siamo a tua disposizione per un’analisi cucita su misura per le tue esigenze.





